在測試工程中,「重現 bug 或性能問題」是日常工作之一,尤其當資料表出現碎片化時,效能問題往往悄然浮現。這次的目標是要探討資料表碎片化是否會導致效能瓶頸,並透過 K6 的效能測試工具來觀察實際結果。本文將帶你從建立環境到效能測試的完整流程,深入了解碎片化對 PostgreSQL 資料表效能的影響。
在這次的刻意練習中,我們將模擬資料表碎片化的情況,並深入探討它對查詢效能的影響。透過操作 PostgreSQL 資料表進行大量的刪除與更新,觀察系統效能瓶頸的產生過程,並運用 K6 進行效能測試,幫助我們量化並分析碎片化對系統查詢效能的具體影響。
首先必須了解資料表碎片化的原因並且試著重現,並且要知道如何查詢資料表碎片化的數據和結果,我把過程分為下列幾個步驟:
當資料表發生頻繁的更新和刪除時,特別是對「users」表的大量操作(例如,刪除一半的資料並更新另一半),會導致資料表內產生「死亡的資料列」(dead rows)。這些死亡的資料列無法被即時回收,除非透過像是 VACUUM 或 VACUUM FULL 的清理動作。這些死亡的資料列會導致查詢的效能下降,尤其當表格持續膨脹時。
首先,使用 Docker 來啟動一個 PostgreSQL 容器,並建立一個名為 users 的資料表。
docker run --name PerfPostgres -d -p 5432:5432 -v ~/Postgres:/var/lib/postgresql/data -e POSTGRES_DB=perf -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD='postgres' postgres:latest
在 PostgreSQL 中,自動清理 “dead rows”(死亡的資料列)的過程主要是透過 Autovacuum 完成的。Autovacuum 定期檢查資料表並執行 VACUUM 和 ANALYZE 來清理死資料列和更新統計資料。如果你想關閉這個自動清理的功能,可以透過調整 PostgreSQL 的參數設定來達成。
關閉特定資料表的 Autovacuum
ALTER TABLE users SET (autovacuum_enabled = false);
在 server.ts 製造出一個有碎片化的 users 資料表,這邊也可以選擇使用 SQL 直接新增大量的假資料,但我選擇沿用之前的 server.ts 在 initialize databse 是建立 users 資料表並插入大量假資料:
const initializeDatabase = async () => {
try {
await pool.query(`CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT,
email TEXT
)`);
await pool.query('CREATE INDEX IF NOT EXISTS idx_users_name ON users(name)');
// 新增大量資料來模擬效能瓶頸
await pool.query('BEGIN');
const insertQuery = 'INSERT INTO users (name, email) VALUES ($1, $2)';
const client = await pool.connect();
try {
for (let i = 0; i < 100000; i++) {
await client.query(insertQuery, [`User ${i}`, `user${i}@example.com`]);
}
} finally {
client.release();
}
await pool.query('COMMIT');
console.log('Table initialized with data.');
} catch (error) {
// 將 error 顯式轉型為 Error 類型
if (error instanceof Error) {
console.error('Error initializing database', error.message);
} else {
console.error('Unknown error', error);
}
}
};
接著模擬大量的刪除和更新操作,以產生碎片化。
DELETE FROM users WHERE id % 2 = 0;
UPDATE users SET email = 'updated_' || email WHERE id % 2 = 1;
這會導致 users 表中產生大量的死亡的資料列。
SELECT
schemaname,
relname AS table_name,
n_live_tup AS live_rows,
n_dead_tup AS dead_rows,
n_dead_tup / nullif(n_live_tup, 0) AS dead_ratio
FROM pg_stat_user_tables
WHERE relname = 'users';
這邊是使用 pg admin 和 SQL 查詢出來的結果:
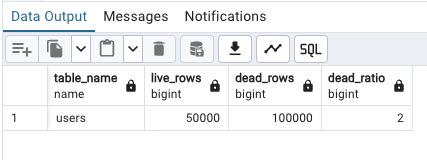
這段查詢會顯示活資料和死資料的比例(dead_ratio),幫助我們了解碎片化的嚴重程度。
碎片化的嚴重程度通常依賴於以下因素來評估:
安裝 K6 並建立一個簡單的測試腳本來模擬大量的 GET /users API 請求。
首先,安裝 K6:
brew install k6
接著,撰寫一個簡單的測試腳本 fragmentation-test.js:
import http from 'k6/http';
import { check, sleep } from 'k6';
export let options = {
vus: 30, // 模擬 30 個使用者並發
duration: '60s', // 持續 30 秒
};
export default function () {
let res = http.get('http://localhost:3001/api/users'); // 連接到你的 API 端點
check(res, {
'status is 200': (r) => r.status === 200,
'response time is < 200ms': (r) => r.timings.duration < 200,
});
sleep(1);
}
在命令列中運行 K6 測試:
k6 run fragmentation-test.js
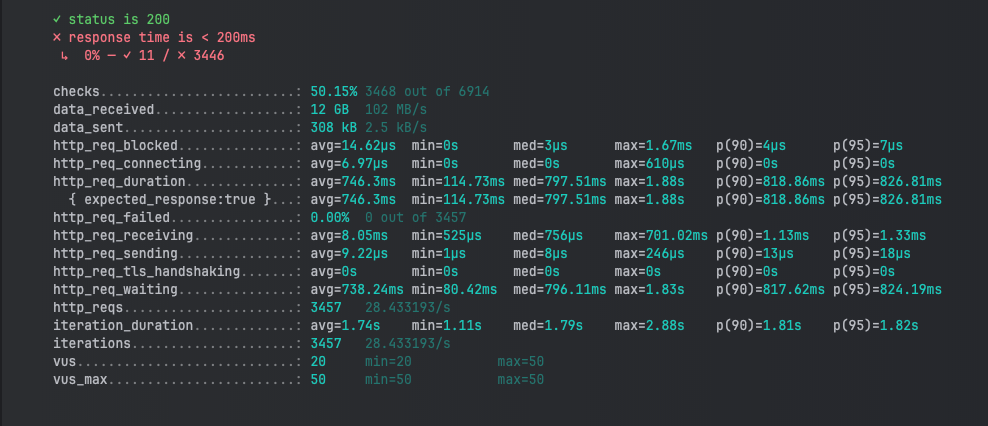
當效能下降時,你可以使用 VACUUM FULL 或 VACUUM 來清理資料表:
VACUUM users;
清理後再使用 K6 測試,觀察效能是否有所提升。
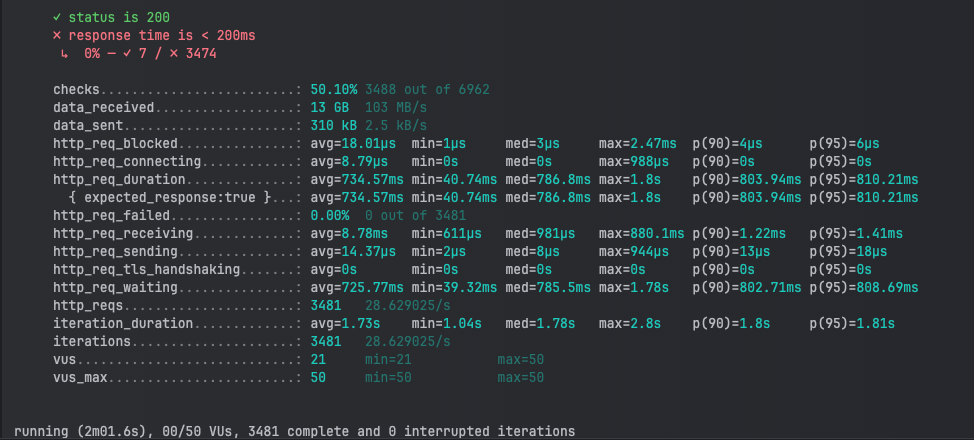
在這次測試中,我們觀察到在有碎片化的情況下,整體的平均回應時間(746.3ms)比無碎片化的情況(734.57ms)略有增加。雖然數據差距看似不大,但在實際應用中,隨著系統負載增大,這種小幅度的延遲累積將可能轉化成較大的效能瓶頸。
有趣的是,無碎片化的情境下資料接收量稍微增加(從 12 GB 到 13 GB),這可能是因為資料表經過清理後,數據能夠更快速、穩定地處理,降低了系統內部的重複讀取行為。
在查詢每秒處理的請求數量上,兩次測試結果非常相近,約為每秒 28 次請求。這表示即便資料表出現碎片化,吞吐量並未立即受到嚴重影響。但可以推測,隨著更多碎片化累積,未來的查詢效能可能會進一步惡化。
為了進一步模擬更高程度的碎片化,你可以:
增加刪除與更新操作的頻率與範圍:將刪除和更新操作的比例從原來的 50% 提高到 75% 或更高,這樣會產生更多的死亡的資料列。同時,也可以嘗試在多次的更新操作中,使用不同大小的資料,這樣資料表中的資料分佈會變得更不均勻,加劇碎片化的現象。
例如:
DELETE FROM users WHERE id % 4 = 0;
UPDATE users SET email = 'updated_' || email WHERE id % 4 = 1;
模擬大型應用的資料寫入模式:如果你的應用程式會頻繁地新增和更新資料,你可以設置定期批次插入資料的操作,並在批次插入後隨機刪除一部分資料,這樣會更接近實際應用場景下的碎片化程度。
const bulkInsertAndDelete = async () => {
await pool.query('BEGIN');
const insertQuery = 'INSERT INTO users (name, email) VALUES ($1, $2)';
const deleteQuery = 'DELETE FROM users WHERE id % 3 = 0';
const client = await pool.connect();
try {
for (let i = 0; i < 10000; i++) {
await client.query(insertQuery, [`User ${i}`, `user${i}@example.com`]);
}
await client.query(deleteQuery);
} finally {
client.release();
}
await pool.query('COMMIT');
};
這次測試結果清楚地顯示出,雖然碎片化對 PostgreSQL 資料表的即時效能影響在短期內可能不會非常明顯,但長期來看,隨著資料表不斷增長,碎片化將成為效能瓶頸的隱患。定期進行資料表的 VACUUM 或 VACUUM FULL,並監控死亡的資料列的累積情況,對於維持資料庫的效能執行其實還滿重要的。


 iThome鐵人賽
iThome鐵人賽